Today, Alts community member Dr. David Baines of Pantile Asset Research explains what’s really happening at the intersection of AI and finance.
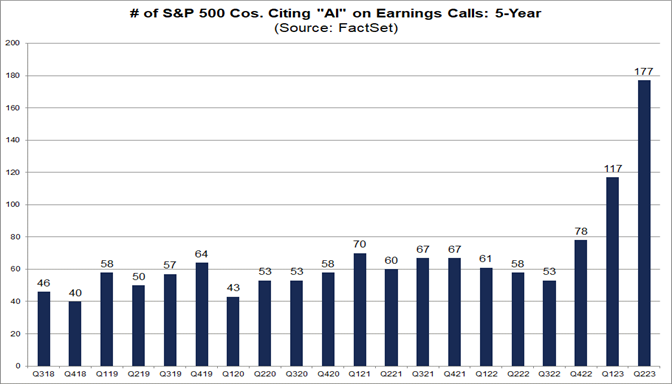
We live in a time of buzzwords. The number of S&P 500 companies referencing “AI” on Q2 earnings calls is the highest it’s ever been:
As an outsider, it’s easy to get lost in all these new tech acronyms & phrases. AI. LLMs. Machine learning. Deep learning. GPUs. NLPs.
But as investors, we need to think about what this rapid evolution means.
Given David’s unique position as an academic researcher in deep learning (MBA in Finance, DBA in Finance, PhD candidate in Computer Science) as well as a founder and principal of a quantitative investment firm, David is happy to offer his perspective to the Alts community.
We hope it’s useful to you and your investing theses.
Let’s go 👇
Note: David runs Pantile Asset Research, a quantitative investment company that uses data science, AI, and investment theory to research, create, and manage trading strategies for institutional investors. He is currently earning his PhD in Computer Science from the University of Colorado Boulder. He also holds a Doctorate in Finance from Washington University in St. Louis, and an MBA in Finance from Boston University.
Table of Contents
A primer on AI (to sound smart at cocktail parties)
Without a doubt, these are exciting times in this field.
But, as we’ve seen before, it’s important not to get too carried away with the headlines, and to have a solid understanding of these new technologies and their applications to engender effective investment outcomes.
At the very least, I’ll make things easy to understand, so you can sound smart at cocktail parties. 🍸
AI isn’t new at all
First, let’s remember that artificial intelligence (AI) is not new.
While revolutionary products such as OpenAI’s ChatGPT in Nov 2021 and the rise of graphical processing unit resources (GPUs) from companies like Nvidia (which powers such releases) have saturated the headlines lately, AI has really been around since the 1940s.
It started with machines like “the Bombe” – a primitive yet revolutionary analog computer developed by British mathematician Alan Turing in the early-1940s.

Computing power has always been a key blocker
AI’s capabilities are limited by raw computing power.
In my opinion, it’s the abundance of this computing power, along with the robustness of data, which has finally combined to fuel today’s AI explosion.
That’s why AI is flourishing and NVDA is popping off: GPUs are just way better at AI computation than CPUs.
The AI hierarchy
AI researchers think about their work as a hierarchy.
At its broadest, “AI” is just the ability of a machine to make a decision. That’s it.
Now, this could be as simple as having Excel choose a random number between 1 and 3 so it can play “rock, paper, scissors,” or as complex as the new generative AI applications we have today, such as ChatGPT or the image-creation product Pixlr.

But how the heck does the AI model generate these outputs?
I’ll get nerdy for a second, but keep it high-level.
The first step: GPTs
So, GPT stands for “generative pre-trained transformer” which, in plain English, means ChatGPT takes in prompts provided by the user, and given what the model has seen and “learned” in the past, generates an output.
For example, let’s say the model has seen the phrase somewhere on the Internet, “Abe Lincoln is the most prolific president in United States history!”
When a user asks, “Who is the most famous president in US history?”, the model will return, “Abe Lincoln is the most prolific president in US history.”
Interestingly, this is where Google ran into trouble last week. Their “AI Overviews” feature worked well for common searches. But for uncommon searches where there’s an “information gap,” the results were disastrous.

Google’s full explanation is worth reading.
Regardless, the method by which a computer learns the relationships between sequential words from info it has seen somewhere before is called a transformer.
We call this learning and analysis natural language processing (NLP). And when these NLP models get really large, we call them large language models (LLMs).
Okay, now that you’re an LLM pro, let’s get back to the AI hierarchy.
The second step: Machine Learning
The second step deeper into the AI hierarchy is machine learning (ML).
ML is basically the process of learning patterns and relationships
ML models learn the relationship between two or more pieces of data. This allows them to both explain and (if they’re good) predict data.
Let’s say you have the letter grades of students at a university, and the number of hours each student studied that semester.
That relationship could then be used to either explain the letter grades as a function of hours studied, or even predict a letter grade given the number of hours studied for a student.
Again, this has been around for a while. But the raw amount of data we can feed the machines means they can get pretty good at explaining and predicting.
The third step: Deep learning
Finally, the newest component on the hierarchy of AI is called “deep learning.” This is where I live in my research, and the work I do at my firm.
Deep learning is like machine learning on steroids.
It involves:
- Extremely large datasets
- Very difficult-to-compute relationships (such as the relationship of intraday stock prices to quarterly company results)
- Algorithms that need to iterate over many, many outcomes to find meaningful relationships.
How is deep learning actually used in finance?
Before we talk about deep learning in finance, let’s talk about how machine learning is used in finance.
An example of machine learning in finance would be calculating the probability that someone gets approved for a loan, based on their income, credit score, debt-to-income ratio, years employed, and whether they own or rent their home.
This is called “binary classification.” You’re basically predicting if the outcome is YES or NO based on past approvals and denials (and the data that influenced those decisions.)
The math is straightforward, the data is simple, and the model isn’t too complicated.
However, deep learning in finance would be a model that, say, reads an earnings call transcript from a company and recommends whether or not you buy their stock.
But doing this effectively is far, far more complicated.
First, the model needs to turn text into numerical values (this is called “embedding”). Then, it needs to determine which numerical values are most highly correlated with signals that drive buying and selling behavior.
These signals could be stuff like earnings projections, or even the use of words like “bullish”, “beat”, “tailwinds”, etc.
Yes, this is all possible with current AI technology. But these models are much more complicated to create, and take far more engineering and training to deploy well.
As you’d expect, deep learning is where all the “cool” advances in AI and finance are happening.
Generative AI
Definition:
Using AI models to create something new from a user prompt or data.
Practical finance applications:
- Converting market events into white papers for investors in real-time (This is one thing my company is building!)
- Creating plots and graphs from finance data automatically for analysts and investors (like Kensho technologies)
- Converting earnings calls to buy and sell signals in real-time (like Amenity Analytics)
Image recognition, detection, and segmentation
Definition:
Analyzing images and classifying the image, called recognition (“this is an image of a cat”), finding an object in an image, called detection (“this image contains a cat”), and segmentation (“this part of this image is a cat, and this part is not a cat”).
Finance applications:
- Looking at Google Earth images to count the number of cars in a retailer’s parking lot to determine buying patterns. (like Orbital Insight)
- Scanning images on the shelf of a retailer in real-time then, adding them to a digital “cart” as you take them, and reducing the need to checkout the traditional way (like Amazon Go kiosks)

Classification
Definition:
Determining unique classes in numerical or text data.
Finance applications:
- Parsing through account history and analyzing spending and earning behavior to determine the creditworthiness of borrowers.
- Analyzing technical indicators from stocks to determine if they’re “oversold” or “undersold.”
Summarization and extraction
Definition:
Analyzing a large amount of data and extracting or summarizing numerical features, sentences, or even topics & ideas.
Finance applications:
- Summarizing a company’s earnings call as a buy or a sell based on the language used by the executives
- Providing “answers” to common situations or questions relating to a banking account, mortgage application, or investment thesis. (Chatbots)

The problem with using AI in business
I typically see two primary uses of AI: automation to make rote processes quicker or more cost-efficient, or analysis to make more data-driven decisions.
- For automation, the most common use case I see is the (dreaded) chatbot which uses a tree of common questions and answers to provide less-expensive and faster customer support.
- For analysis and insight, teams will attempt to provide empiricism for decision-making given data produced by, or purchased by, the company.
In both instances, however, it takes a combination of AI modeling, systems design, and general programming knowledge (as well as company and industry-specific domain aptitude) to achieve effective results.
This is where companies are struggling most right now.
For the most part, companies assemble “data science” teams into two separate groups:
- AI teams that know how to solve the problem, and
- Domain experts that know what the problem is given their knowledge of the business.
But putting these two (very different) skill sets together to form a cohesive, effective output has proven challenging for companies.
I’ve personally been a part of these mash-up teams a few times. So far I’ve seen these teams produce AI solutions that are square solutions for round problems, or solutions that actually degrade the customer experience instead of enhancing it.
These are growing pains, and I’m confident this will improve with time. But companies need to figure out where AI teams sit within an organization, and who they should report to.
The problems with using AI in finance
Hiring is tough
At my fintech company, I look for candidates with deep experience in economics and finance, as well as deep expertise in data science, computer science, and AI modeling.
This is critical for us, because using AI requires a deep understanding of both given the complexities of the business side of our industry as well as the complexities of the data side of it.
But given the traditional education and industry paths that exist today, we’re (admittedly) finding it hard to find folks who understand both what problems need to be solve & how to solve them.
In my opinion, this is what’s holding back AI in finance.
Nuanced preferences
Sure, AI could potentially build portfolios for retail investors based on their (stated) preferences.
But, if you think about it, how many preferences actually go into such a portfolio? Risk? Liquidity? Sector exposure? Volatility? Downside tolerance? Specific company preference?
When you take all this into account, the investor is left thinking “Look, I just want to talk to someone about all this.”
Interpretation is tricky
Furthermore, data in finance is extremely fragmented and difficult to interpret, which can lead to erroneous AI outcomes.
Even simple items like pricing data can be difficult to interpret. Is it the raw price or does it include dividend disbursements? Does it take stock splits into account over time? Is it the average price in the market or a particular price, maybe the most executed price, in the market? Etc.
Remember that, at any given time, stocks are bought and sold for numerous prices, which is called the “limit order book.” These complications make using AI in finance very difficult relative to other domains.
Trust is critical and lacking
Companies need to keep in mind that understanding your customer is everything.
In finance, customers and clients require trust in their financial service providers — whether it’s their RIA, CPA, or insurance provider — and AI is still in its place where lots of folks just don’t trust it yet.

The fact is that clients have a wide array of preferences for products, risks, objectives, and concerns, and AI is still not at the point in its evolution where it can mimic the human touch that an investment advisor can provide (although firms such as Wealthfront are trying through their “robo-advising.”)
This trust dynamic will change and evolve over time, but trust in our industry’s approach is paramount because any technology used in that approach is managing our clients’ savings, not their dinner reservations.
In other words, the margin for error is very small and the reputation lost from making mistakes could be very large.
You may have heard the saying “garbage in, garbage out,” which certainly applies here. As mentioned previously, it takes a very deep understanding the data, how to use it, and what it represents in an economic sense before we even start to model a market dynamic.
For example, I could model price predictions for Apple (AAPL), but it would be a mistake to translate that prediction model to Disney (DIS) because they’re in different markets, and have different strengths and weaknesses. Yet, I see that these price models are often simply translated from one underlying asset to another, which provides spurious results.
If we get any of those facets wrong, it can violate the trust effect described above.
These issues are why my current doctoral research specifically uses these advanced deep learning approaches (such as neural networks, LLMs, and GPTs) within finance and economics.
Because it’s these domains which have a ton of inherent theoretical and practical nuance that materially affect AI results.
The problems with AI in investing
“AI in investing” can mean all sorts of things.
Typically, companies and investors use AI for the same tasks as other industries: the automation of dull processes, finding relationships in data, summarization and extraction of data, or basic price predictions.
In other words, markets and their prices are just the byproduct of human behavior (behavior of buyers and sellers), which is very unlike a physical or language-based system such as translation services or autonomous vehicles.
But AI in finance is difficult because there are no completely reliable, immutable laws in market systems; and furthermore, markets don’t necessarily repeat themselves. All of these properties are fairly necessary conditions in AI modeling.
Recent developments in AI modeling
That said, some interesting, very recent advances in AI modeling allow us to mathematically model markets as “adversarial games.” This is the basis of my current research.
In an adversarial game (like chess), you have clear winners and losers. We can provide mathematical formalism to determine the optimal way these games should be played, and researchers such as myself are working to fit this way of thinking into financial market systems.
For example, I’m working on a paper that attempts to predict near-term price movements as a function of the market participants’ buying and selling behavior — and their ability to absorb and properly price market information.
While my approach is new, the concept that “prices reflect available information” is not. That honor goes to economist and asset pricing professor Eugene Fama, whose seminal work was published back in 1970.
Another paper I’m working on attempts to solve for the optimal stop loss price in a trade — a mathematical problem which has yet to be solved, but one which every trader employs heuristically daily.
Both use a little-known field of AI called reinforcement learning which considers learning problems to be reward-based (as opposed to simply patterns found in historical data.)
Sorry I can’t share these papers yet! But this is exciting stuff, and I look forward to bringing the fruits of my work to my clients at some point in the near future.
Alternatives will be a tricky nut to crack
I also love alternative investing — one of the reasons I joined Altea last month was to share my research and learn a ton from others).
But remember that AI thrives on data. So AI in investing is best for asset classes with a ton of data. This means mainly liquid securities such as stocks, commodities, crypto, and bonds.
Illiquid asset classes such as real estate, private equity, venture capital, and other bespoke alternatives are much more difficult to perform AI-based analyses on (since the data is so thin.)
I attend a conference regularly that gets practitioners and academics together to try to provide data for research in this area. There is active research to solve this problem, both in terms of finding how to create and disseminate data in private investments, and also how to analyze and truly learn from it at a massive scale.
But this research is very recent, and typically requires firms in the private equity, real estate, alternatives, and hedge fund space to provide it (which they are hesitant to do)
Closing thoughts
AI is a powerful tool that isn’t going anywhere.
Unfortunately, much like any other technical revolution, we’ll have to wade through misunderstood buzzwords, bloated claims, and bad actors which aim to use the technology for nefarious purposes.
But on the whole, AI can help people learn more, be healthier, be more productive, and even have more time for themselves and their families.
While there is much work to do to figure out how to make AI more performant, trustworthy, unbiased, and reliable, the beauty of researching and developing this stuff is that the more we learn we learn as humans, the more we can improve our processes and approaches.
Which, I suppose, is just like an AI model. ✨
That’s all for today.
If you’d like to ask a question about my company or research, or just want to chat or say hi, my email is [email protected].
You can also find me on LinkedIn, or just reply with comments. We read everything.
See you next time, David

Disclosures
- This issue was sponsored by Rootless.
- This issue was authored by David Baines from Pantile Asset Research.
- Neither the author nor the ALTS 1 Fund, nor Altea has any holdings in any other companies mentioned in this issue.
- This issue contains no affiliate links.